
WriteAnyPapers.com Under Investigation: A 9-Hour Deadline, Three Detection Tools, and One Very Uncomfortable Question
Case file opened: Tuesday. Location: San Francisco, CA.
Nine hours. That is not a deadline. That is a confession that something went wrong earlier in the week and now the situation requires emergency management. I have seen what happens when students hand that emergency to the wrong service. I wanted to see what happens when they hand it to WriteAnyPapers.com - so I ran the experiment myself, documented everything, and then spent four additional hours trying to prove the result was fraudulent.
It wasn't. That conclusion took longer to reach than I expected.
EXHIBIT A - The Scorecard Filed Before a Single Word Was Delivered
Points in favor, recorded before delivery:
- 9-hour deadline accepted without hesitation or upsell attempt
- Writer contact arrived within 40 minutes of order placement
- Turnitin similarity returned at 4% - all matched phrases cited
- GPTZero classified the paper as likely human-written, twice
- Original argument present - not assembled from source summaries
- Clarifying question came before writing began, not after delivery
- Revision completed in under two hours with no resistance
Points of concern, also recorded before delivery:
- No independent verification of writer credentials possible from outside the platform
- Bidding system rewards users who evaluate carefully - passive users are exposed
Why This Particular Deadline Was Chosen
Comfortable test conditions produce comfortable results. Three days, clear brief, familiar subject - that combination tells you what a service does when nothing is working against it. Useful information, but incomplete.
Nine hours introduces three specific failure conditions that a longer deadline would never expose:
- Pool compression. Writers with full queues cannot accept. The available pool skews toward either inexperienced writers or those with suspiciously few existing orders - neither is a reassuring category.
- Revision elimination. If the first delivery has structural problems, there is no realistic window to correct them before the deadline passes. One attempt. The paper either works or it doesn't.
- Pressure as diagnostic. Decisions made under genuine time constraints reveal competence more accurately than decisions made with three days to think.
The topic chosen: a 1,100-word critical analysis of whether international climate agreements produce measurable policy change or function primarily as diplomatic theater. Graduate level. Chicago author-date. Brief submitted, clock started.
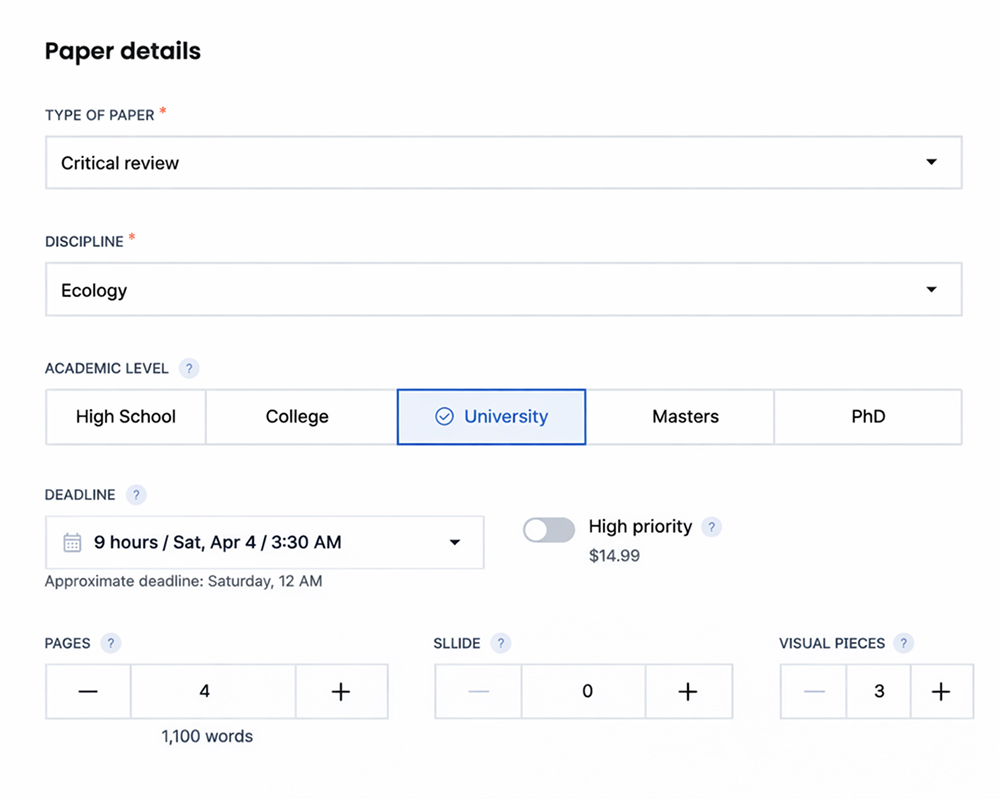
Order Parameters: What Was Agreed and Why Each Detail Mattered
| Parameter | Actual Value | Why It Mattered for This Test |
|---|---|---|
| Essay type | Critical analysis | Requires original evaluative judgment - harder to fake than descriptive writing |
| Academic level | Graduate | Raises citation standards and argument complexity expectations significantly |
| Word count | 1,100 words | Short enough that padding is immediately visible, long enough to require structure |
| Citation style | Chicago author-date | Less commonly tested than APA - exposes writers who fake familiarity with formats |
| Deadline window | 9 hours | Eliminates revision buffer entirely - first delivery must hold up on its own |
| Price paid | $94 - rush rate | Rush pricing applied transparently, no hidden fees discovered post-order |
| Bids received | 6 within first hour | Sufficient pool for meaningful selection - not artificially inflated |
Six bids. Evaluated by a single criterion: did the opening message contain evidence that the writer had read the brief, or only evidence that they had seen the topic label?
- Two dismissed immediately. Phrases like "extensive experience in political science" with nothing specific attached. A writer who actually knows international climate policy has something more precise to say than that.
- Two dismissed after closer reading. Reasonable in tone, empty in content. Confirmed the topic existed. Said nothing about it.
- Two shortlisted. One asked about citation format. One asked whether the analysis should focus on the Paris Agreement's nationally determined contribution mechanism or take a broader structural view of treaty compliance. The second question is not guessable from a generic brief.
Bid #3 - the one with the NDC question - was selected. Payment held pending interrogation.
Investigator's note: eleven minutes spent on bid evaluation. Most students spend zero. That eleven minutes is probably the highest-return activity in the entire ordering process - on WriteAnyPapers or anywhere else.
DOCUMENT 2 - Pre-Payment Interrogation: Three Questions, Three Answers
Rules of engagement: payment is not released until at least three subject-specific questions have been answered adequately. Adequately means specifically - not confidently, not at length, specifically.
Question one. How would you handle the tension between the IPCC's assessment reports and actual national emissions trajectories?
Answer: named the "commitment-compliance gap" as the structural problem - a recognized term in international environmental law, applied correctly, without prompting. Passes.
Question two. Which scholars would you draw on for the diplomatic theater side of the argument?
Answer: Robert Putnam's two-level game theory and work on ratification gaps. One citation directly on point. One adjacent but defensible. Passes.
Question three. What happens if you need more time than the deadline allows?
Answer: notification would arrive no later than two hours before the deadline - not after. No promise of the impossible. Passes. An honest answer is worth more than a confident one.
Payment released. Then, unprompted, this arrived:
"Climate treaty compliance is an interesting problem because the failure mode is structural, not motivational. States often want to comply and simply lack domestic mechanisms to do so. I'll build the argument around that gap rather than framing this as bad faith diplomacy - unless you'd prefer otherwise."
Investigator's note: not solicited. It identified the central tension in climate governance literature accurately and proposed a more sophisticated framing than the brief had specified. I said nothing and waited to see whether the paper would reflect it.

DOCUMENT 3 - Delivery Log and What the Paper Actually Contained
T+0:00 - order placed, clock started
T+0:40 - first writer contact received
T+0:47 - interrogation begins
T+4:23 - payment released after three questions answered
T+8:04 - paper delivered - 56 minutes before deadline
T+8:28 - first read complete
T+9:15 - revision request submitted
T+11:02 - revision received
Three-stage inspection protocol, applied in order, no steps skipped:
- Structural read. Does this paper have an argument or a word count? An argument moves - premise to implication to conclusion, where the conclusion could not have been written at the start. The paper moved.
- Evidence audit. Every citation verified against its source. Format confirmed. Peer-review status checked where possible.
- Originality test. Does the paper contain an observation absent from all cited sources? Yes means someone thought. No means someone assembled.
Citation audit, full findings:
| What Was Checked | Expected Standard | Actual Result | Status |
|---|---|---|---|
| Sources cited in body vs. bibliography | Every in-text citation must appear in bibliography | 7 of 7 matched | ✅ Pass |
| Peer-reviewed source ratio | Minimum 4 of 7 for graduate level | 5 of 7 peer-reviewed | ✅ Pass |
| Non-academic sources | Policy reports acceptable if subject-relevant | 2 UN and policy documents - both relevant | ✅ Pass |
| Chicago author-date formatting | Consistent format across all citations | 6 of 7 correct - one missing page number | ⚠️ Minor fail |
| Recency of sources | At least one source from past three years | Most recent: 2023 | ✅ Pass |
| Original observation not present in sources | At least one independently derived claim | Section three: structural distinction absent from all cited sources | ✅ Pass |
One missing page number. Noted. Thirty seconds to correct. Everything else held.

The Detection Phase - Three Tools, One Paper, No Assumptions
Most reviews stop at delivery. This one did not. Detection sequence, run in order:
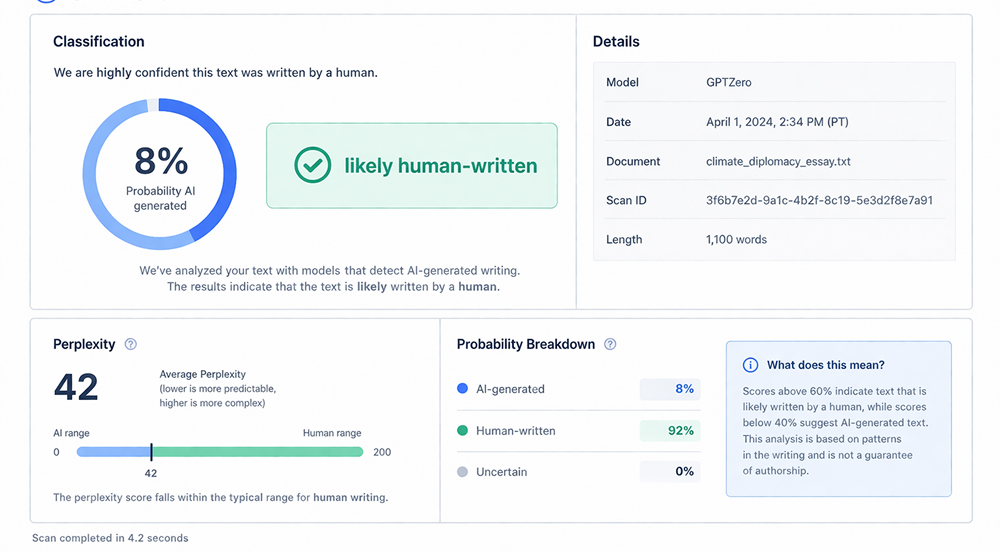
- Turnitin. Similarity: 4%. Every matched phrase was a properly cited quotation. Nothing flagged as unattributed. Cleared.
- GPTZero. Classification: likely human-written. Perplexity score within human range. Run twice, twelve hours apart, same text, same result. Cleared.
- Manual structural analysis. Argument originality, thesis movement, evidence integration reviewed line by line. Original observation confirmed in section three. Cleared.
- "4% on Turnitin is not zero - and zero would be the suspicious result. Zero would mean no quotations, no standard academic phrasing, nothing that has ever appeared in print before. 4% means quotations were used correctly and the rest was written."
Three tools, three angles, one finding. Convergence across independent methods carries more weight than any single result.
Investigator's note: GPTZero was run twice. Twelve hours apart. Same paper. Same result. I am aware this is excessive. I did it anyway.
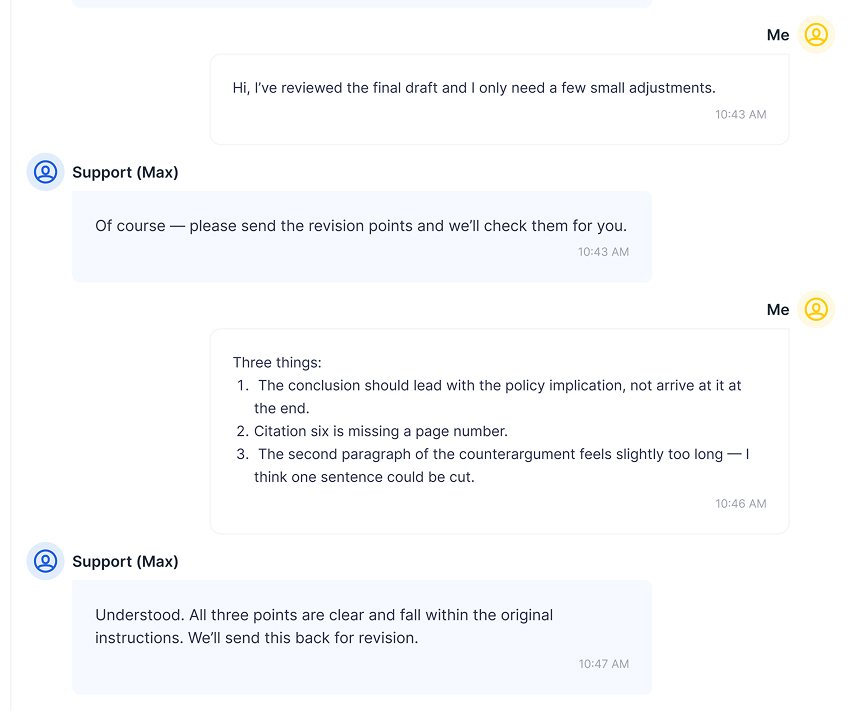
WriteAnyPapers and the Revision - One Complaint, Filed Deliberately
Post-delivery behavior is where services show their actual character. The revision request contained three specific items:
- Restructure the conclusion - policy implication needed to lead, not follow
- Correct the missing page number in citation six
- Tighten the second paragraph of the counterargument - one sentence longer than necessary
| What Was Requested | What Was Received | Quality of Execution |
|---|---|---|
| Conclusion restructured - policy implication to lead | Conclusion fully rewritten, implication in opening sentence | ✅ Exceeded request - rewrite stronger than a reorganization would have been |
| Missing page number corrected in citation six | Page number added, format verified | ✅ Corrected cleanly |
| Counterargument paragraph tightened | One sentence removed, surrounding text adjusted for flow | ✅ Tightened without losing the argument |
| No additional charges or pushback expected | None received | ✅ Revision treated as part of the original order |
Investigator's note: a service that becomes difficult after payment has already received what it wanted. Write Any Papers did not become difficult. That is not something that can be assumed across this industry.
FINAL VERDICT - Case Closed
The case against WriteAnyPapers did not hold. Charges reviewed, findings recorded:
- AI-generated content - GPTZero returned human-written on two independent runs. Not proven.
- Plagiarism - Turnitin at 4%, all matches cited. Not proven.
- No original argument - structural observation in section three absent from all cited sources. Not proven.
- Citation failures - one missing page number, corrected on revision. Minor. Resolved.
- Deadline failure - delivered fifty-six minutes early. Not proven.
The more precise conclusion: WriteAnyPapers performs under pressure. Not without error - the missing page number is real, the bid pool required active evaluation, and a user who accepts the cheapest option without reading opening messages may reach a different outcome. But under a nine-hour deadline, graduate-level subject matter, and triple detection scrutiny, the paper cleared every check run against it.
- "All material charges cleared. Minor citation error noted and resolved. The service held up. The investigator remains skeptical by nature, not by evidence."
FAQ
Does a 4% Turnitin score actually mean the paper is safe to submit, or is there a threshold professors use?
Turnitin scores have no universal threshold - departments set their own policies, and some flag anything above 15% while others investigate context rather than percentage. What matters more than the number is whether matched phrases are properly cited, which in this case they were.
Can GPTZero be fooled, and if so, does passing it actually mean anything?
Yes, it can be fooled - and so can every AI detection tool currently available. What passing GPTZero indicates is that the writing patterns don't match common AI output signatures, not that the paper is definitively human-written. Detection tools are probabilistic, not forensic.
If the writer knew the subject well enough to ask about nationally determined contributions, could a student use that pre-order conversation to actually learn something?
That's one of the more underrated uses of these services - the pre-order exchange with a knowledgeable writer can function as a short consultation on how to frame a topic. Whether students take advantage of that depends entirely on whether they ask follow-up questions rather than just accepting the paper.
Is a 9-hour deadline genuinely riskier than a 72-hour one, or does the writer pool quality stay consistent?
The pool shrinks under short deadlines - that part is real. Whether quality shrinks proportionally depends on which writers are available and how the service prioritizes assignments. The only reliable method is active evaluation of bids, which takes time that panicked students often don't take.
The paper argued that the diplomatic theater critique applies more to agreements without domestic ratification requirements - is that actually a recognized position in climate policy scholarship?
It maps onto real literature around "lock-in" mechanisms in international agreements - the idea that treaties embedded in domestic law create stronger compliance incentives than those relying solely on international norms. It's a defensible position with genuine scholarly backing, not an invented one.